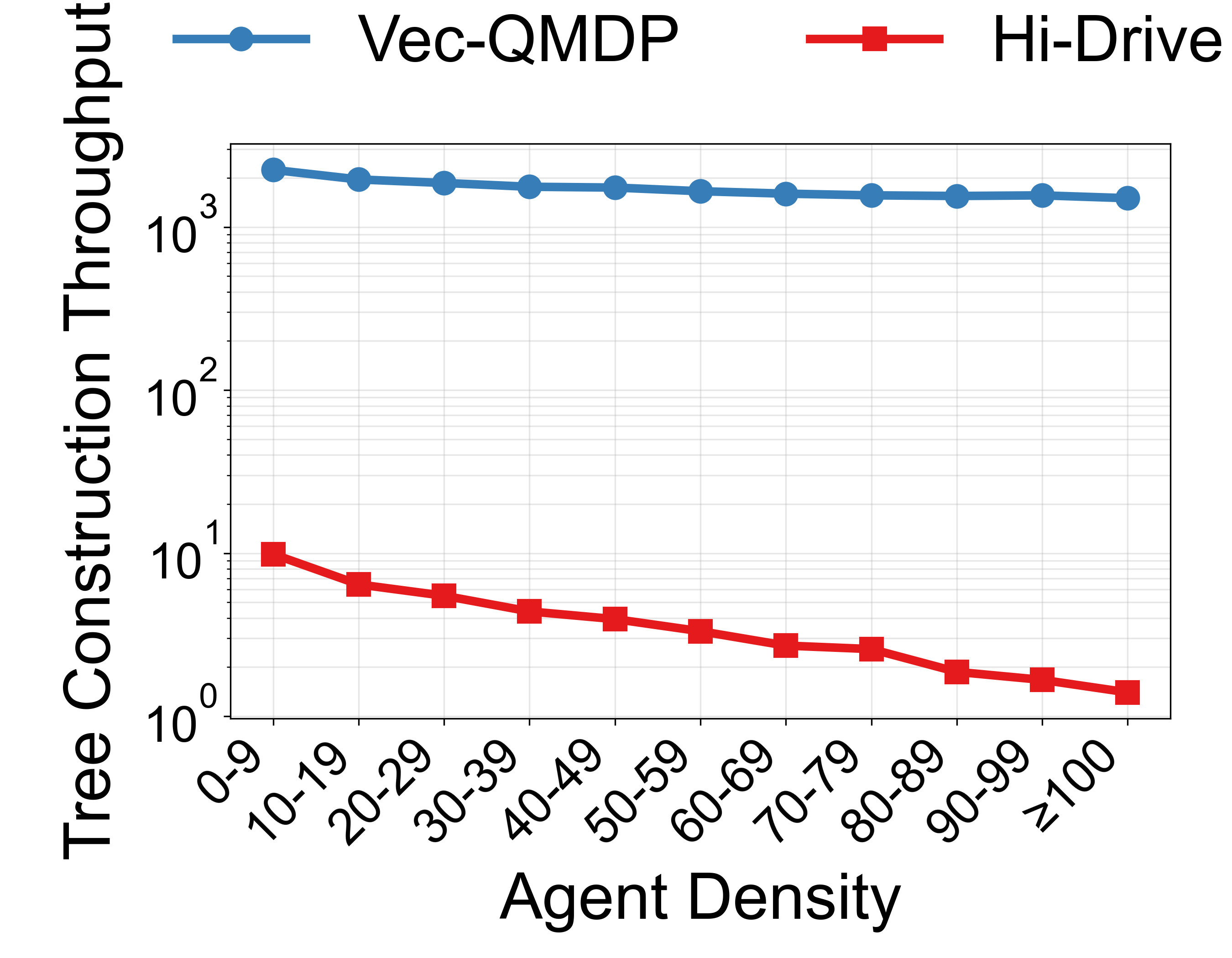
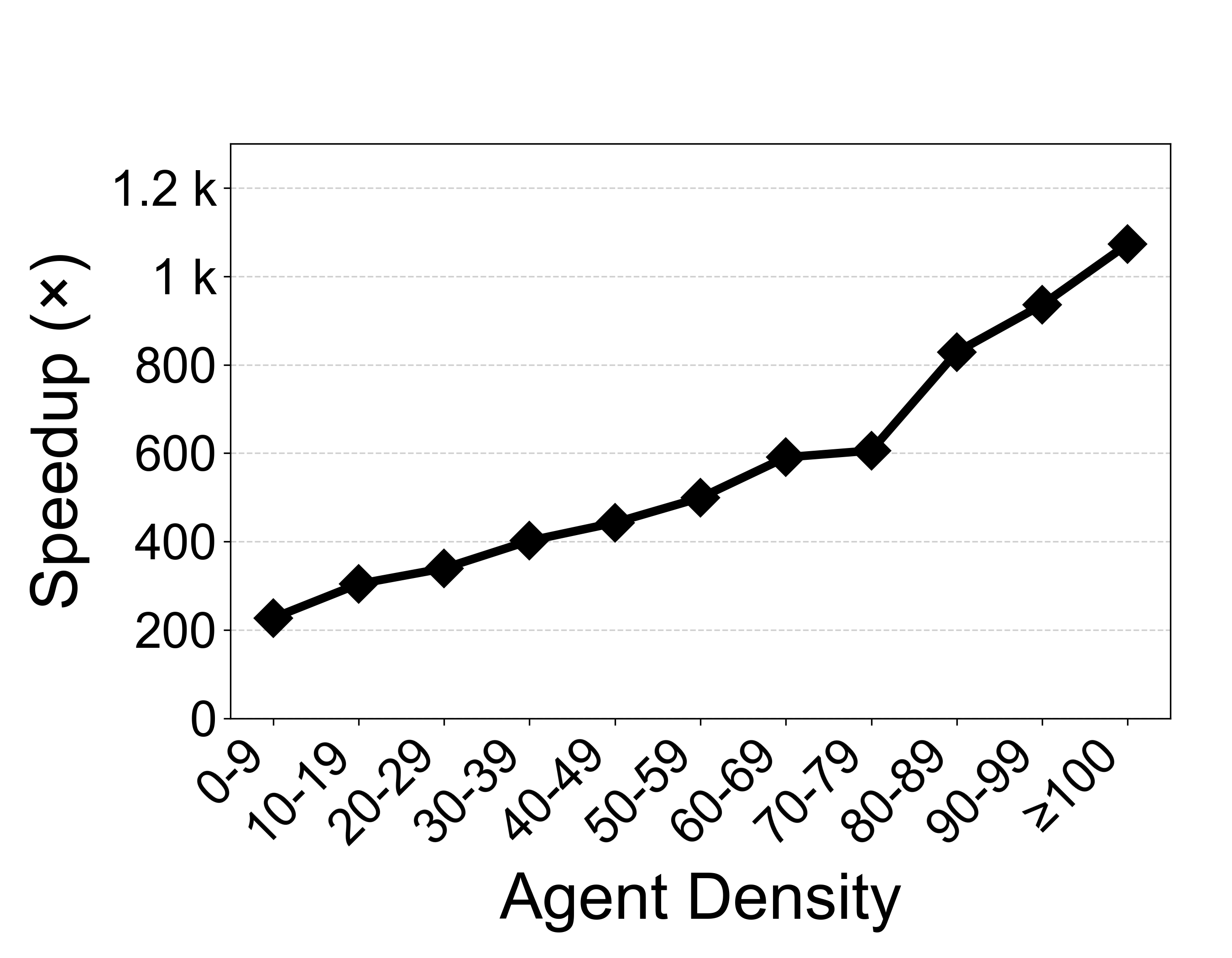
Overview
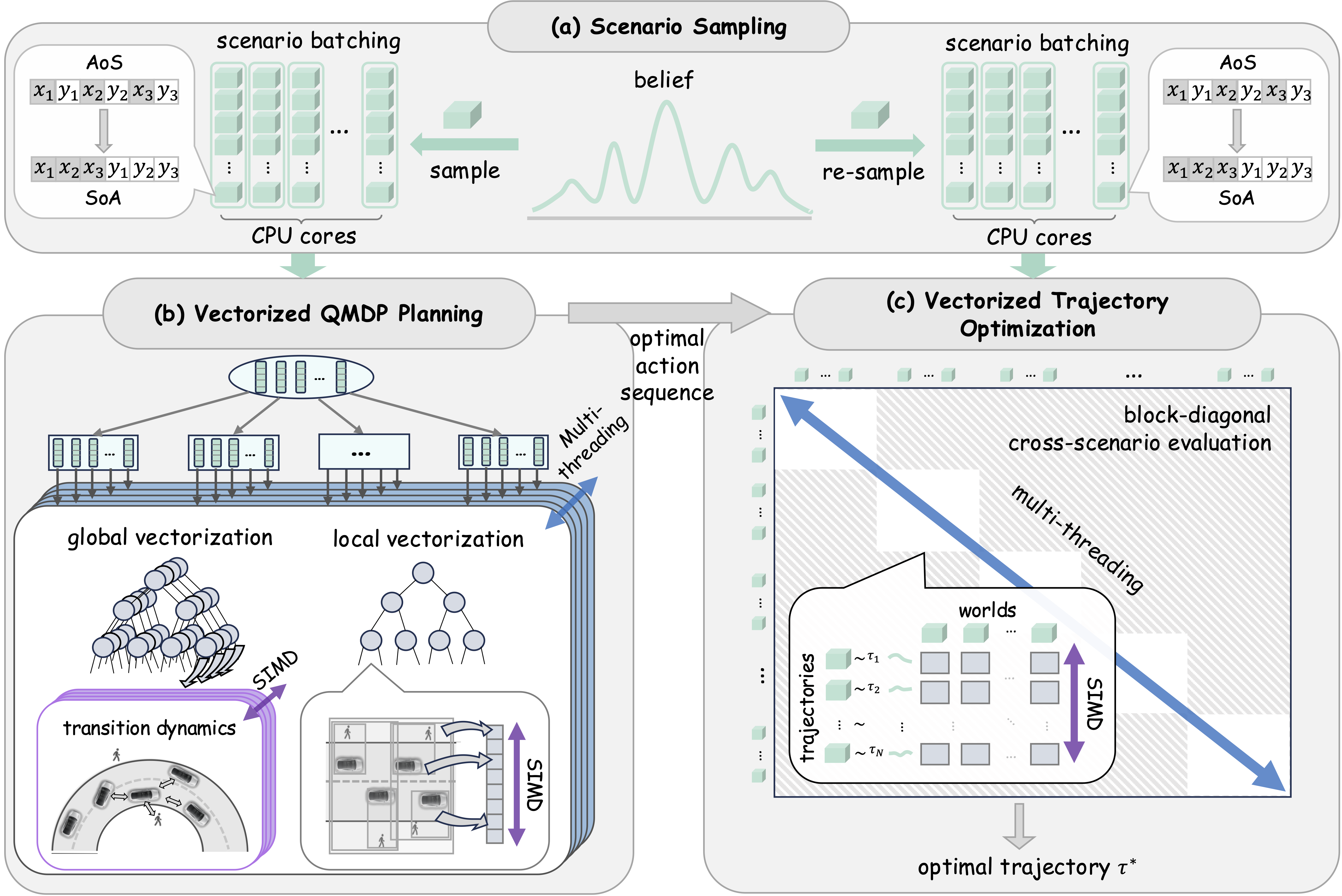
Vec-QMDP scales up a state-of-the-art POMDP planner Hi-Drive for autonomous driving by leveraging SIMD parallelism, demonstrating how belief tree search and belief-space trajectory optimization can be extensively vectorized for robotics tasks in complex dynamic environments. (a) Sample the belief into M × N scenarios in an Structure of arrays (SoA) layout. (b) Vectorized QMDP search: after the first action, scenario trees run in parallel on M CPU threads; within each thread, SIMD global vectorization batches transition dynamics across scenarios and SIMD local vectorization accelerates within-node collision checks. (c) Vectorized trajectory optimization: generate candidates and use block-diagonal cross-scenario evaluation within minibatches to select optimal trajectory.